Image build evolution in EC2
Jukka Dahlbom | 24. marraskuuta 2025

Deploying software on EC2 instances nowadays feel like going backwards in time - most of the applications would be usually preferably deployed as Docker containers or serverless functions. With containers and serverless we wouldn’t have to worry about the instance management but rather just on the application packaging as long as the use case fits the given limitations of the serverless platform or ECS/Kubernetes cluster.
Industrial use cases still more often than not involve running off the shelf software that has been built for physical servers running on-site. Building a cloud environment to run such software in this scenario led me recently back to using EC2 VMs.
No snowflakes
Setting up the environment started off experimentally, but regardless of how experimental system I am building, I’ll never again make the mistake of manually configuring snowflake virtual machines. Snowflake VMs is what you get when you configure the system manually to try out a system prototype, and due to hurry and too much work load, you fail to make the changes into version controlled code.
Downside of the snowflake VMs is that you cannot replicate them, and if you happen to lose one, you cannot rebuild it without a lot of experimenting and trying to remember which essential services are misbehaving without the configuration.
Security requirements also favor immutable infrastructure. Immutability in this case means that we never update the servers themselves. When we need to update something, the whole new machine image is created, released and pushed to production use as an immutable image that is used to launch new virtual machines. We will always exactly know how each VM version is configured because we have the image where we can check it.
Building immutable images also means that the virtual machines we run never need to have access to public internet, as they will never update themselves. They will only ever be replaced. Reality is that there will still be a break-glass SSH access to the servers, and this increases the risk of creating snowflakes in the VM fleet. To avoid this, we intend to both enforce a maximum lifetime of 30 days for the VMs as well as a best before date of 30 days after creation for the machine images. Once a snowflake VM is terminated, it will be replaced by a new VM without any of those modifications. This will at least reveal any temporary local hacks that were needed for fixing an instance.
Playbooks for configuration
To operate a VM fleet with immutable infrastructure properly we need to have automation for creating the images. The starting point towards enabling automation in AWS is writing the whole server configuration into an userdata script file.
I very much prefer to avoid using bash scripts nowadays for full configuration setup, just because they are less modular and too easily become a mess of disjointed script pieces. For ages, my preferred solution for these cases has been Ansible. So in this case, I write my server configuration playbook for Ansible, copy it via S3 to new instances, and run them with the userdata bash script. This is different from how Ansible was originally used as a tool to update fleets of machines, but Ansible supports the local operation well.
Once we have a bash userdata scrip initiating Ansible playbook-based deployment, we already have a modular, version controlled Ansible playbook defining the system changes we want to be running, so we are pretty well off.
Automatic recovery
Next thing to ensure is of course checking that the instances get properly recreated whenever a single VM dies. Whether it is tomorrow or two years from now, they will die.
Autoscaling group is the trusty AWS way of doing this, and the advantage of ASGs is that it supports the userdata scripts easily.
In the legacy software case we usually have to also worry about the state of the system, and in this specific case even the MAC address was significant. This forces us to use a specific type of system, at least when I want to rely on autoscaling rather than have Lambda functions run more complex startup configurations.
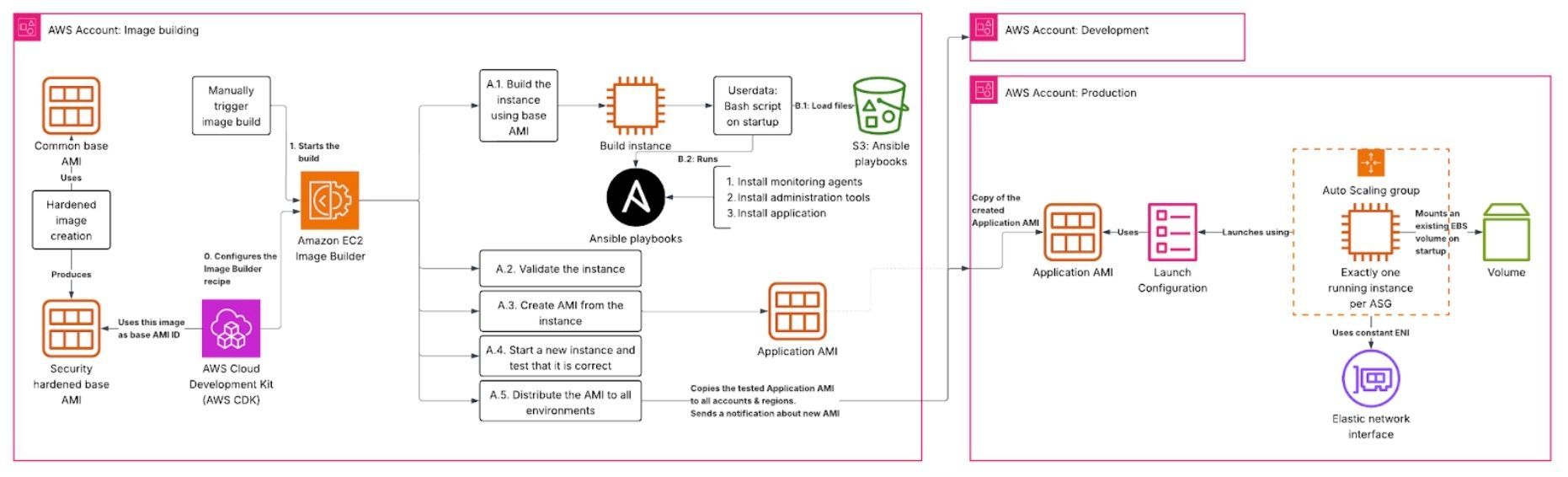
The system state was stored on disk, so we are mounting a persistent EBS data volume on the instance. This had to be done on startup, as ASG does not support mounting specific volumes. As there is only one Volume, I have the ASG running in “Exactly one”-configuration, meaning that the ASG will never spawn more than one instance at a time, and it will spawn exactly one instance if there are none in healthy state. The instance itself will use its own metadata to query AWS API for the correct EBS volume, and mount it on startup.
There is also a requirement from licensing logic that the server must retain its MAC address - this is achieved by configuring the Exactly-one-ASG with a fixed network interface identifier. There is a failure condition where ASG tries to spawn a new instance immediately after the previous one is terminated, because the ENI is not released from the old one yet. I needed to ensure that the ASG will just keep retrying until it succeeds.
One part of the automatic recovery is preparing for low probability but still likely events - in this case the most likely event is the loss of an EBS data volume. Our organization is using AWS Backup to create automatic backups of EBS Volumes, so it is enough to enable the backup by tagging the volume correctly. Now that the backups are getting created, we are good to go after documenting the recovery procedure in case of Volume failure. I chose to store the correct Volume ids in AWS Parameter Store from which the instances query the intended volume id and then attach the volume during startup.
For backup purposes, we can also disable backing up any VMs, as they are immutable and will not have relevant changes that would have to be replicated. Only the data volume contains information worth backing up.
Reliability and speed with prebaked AMIs
Installing the instance with userdata scripts is a reasonable solution for a first automation effort. Even if the security considerations would not require isolating the instances from public internet there are significant downsides to using that solution in a production environment directly, instead of using immutable images.
First issue is the reliability of the build script: With the mindset that everything breaks all the time, we must assume that at some point in time the instances are in state that they cannot connect to package repositories, or other remote resources that they require for installation. Prebuilding a machine image solves this problem: The possible network failures will fail at build time and on a build instance, instead of causing a problem in end user-visible production servers. Second issue is the time required to spin up a new server: If you start downloading updates and for example a 1GB application installation file, it will take a lot longer to get the new instance running. Assuming a moderately bad case of problems with instances, this would occur at a time where the whole redundant clusterful of instances go down at approximately same time, leading to a very long loss of service.
Starting a new instance from a prebaked AMI and only mounting an EBS volume takes about 30-120 seconds. Building a new instance from scratch on an empty OS-image takes anything from 5-20 minutes, depending on the amount of installation we wanted to build.
Third issue that may cause problems is that if you always build the instance upon starting it, you will have a cluster of unique instances which are each running the version of the OS that got installed at the startup time. When you instead build the AMI and use that AMI for all the instances, you will at least have identical base setup on all the instances.
The simplest implementation for building the AMI was to just deploy the instance with build commands in the userdata script, and then using a local shell script to take a snapshot of that VM once it is completed. Fairly quick to do, low development effort, slightly ugly because it will be run on a developer machine or possibly a CI machine.
AWS tooling for building AMIs
Running local scripts is not very suitable for a large team, and it is even less suitable for cases where the responsibility for operating this system will be handed over to an operations team at some point in the future. This is a reality that should be addressed in every project that is intended for production. Very often it gets overlooked if the schedule is tight and there is a pressure to deliver as many working features as possible.
Since our responsibility as developers is to build a clean, understandable and useful system to the people who will be maintaining it, I want to simplify running all pieces of the system into simple UIs that can be explicitly documented in the user manual.
AWS provides the EC2 Image Builder for this purpose. The build components are defined as YAML files, and you can define build, validate and test stages with those components. Ideally you build the AMI in a build stage, validate the recently built instance before creating the AMI and then launch a fresh instance from that AMI to run the test components on it. After this you should have a well tested image that can be deployed via the autoscaling group. Previously I would have used Terraform Packer for this use case, but Image Builder provides a decent UI in AWS console so that is my preferred choice for that reason.
In this case we are using AWS CDK (Cloud Development Kit) to define our infrastructure as code, and there is a AWS-provided CDK library that supports the Image Builder pipeline creation. This lets us easily reference other resources that need to be passed into the build pipeline, such as IAM roles and network interfaces.
Once the AMI is built, the Image Builder also applies sharing and distribution settings to copy the AMI to multiple accounts and regions. This lets us build a single AMI, run functional tests on instances based off that AMI in dev and qa environments and only then deploy the new AMI to production.
Layered image creation
A benefit of using an AMI building pipeline is that we can also split the AMI creation between several responsibilities. The application developers should have to worry only about the working of the application, and any maintenance and security features required by corporate IT should come from corporate IT. In this case we must be compliant with the industry standard security practices, and one aspect of that is complying with the CIS benchmark. We can separate the concerns by creating the base AMI with CIS hardening, reporting and instrumentation, and only then using that base AMI for creating the application AMI. This same hardened base AMI can be used by other teams of the organization, and all application teams benefit from security improvements done on the base image.
Future development
With AMIs getting built automatically by Image Builder, using a layered approach with OS security updates being baked to the first image and application specific configuration on the second image on top of those, we are well off in terms of using infra as code to codify what gets done. The user manual can focus on just the simple tasks of triggering the build pipeline and monitoring the progress of deployments through dev-qa test stages and the deploying to production.
There are still gaps in the automation pipeline that would speed things up and reduce the possibility of errors. Each step should publish their results into EventBridge event bus, and each dependent step should listen for relevant events that should trigger their own build or deployment step.
One straightforward improvement to our system is to move from updating the generated AMI IDs in CDK configuration files to instead updating a SSM parameter store value with the new AMI ID and having the autoscaling group launch configurations refer to that parameter store key directly. This lets us avoid making IaC code changes when we want to do a routine update of the machine image to include latest security updates without actually touching the build configuration. To ensure that the whole instance cluster is using the same AMI, an instance refresh for the autoscaling groups needs to be triggered.
Looking back at the gradual improvement of the build pipeline, it’s easy to see that refactoring older implementations would improve the readability of the whole - for example there is still logic in bash scripts that could be done in Ansible playbooks. Essentially upgrading these components should be done at the latest when we touch those components next time: Developing the whole new abstraction layer is a large task to do, but once it has been done elsewhere in the system, it is a fairly small thing to adapt the old code to the new way of working.
Using reusable and modular solutions for the build pipeline we can also easily present these improvements to our other teams and to the development world as a whole.

Jukka Dahlbom
Senior Cloud Architect
Pilvi haltuun
Huolehdimme pilvestä kokonaisuutena, jotta asiakkaamme voivat keskittyä kasvuun, kehitykseen ja asiakkaisiinsa.
Varmistamme, että digitaaliset palvelut toimivat luotettavasti ja tukevat liiketoimintaa kaikissa tilanteissa.
Uusimmat kirjoitukset


